

Protocol for the Generation of a Transcription Factor Open Reading Frame Collection (TFome)
转录因子开放阅读框收集(Tfome)的生成方法
(*contributed equally to this work) 发布: 2015年08月05日第5卷第15期 DOI: 10.21769/BioProtoc.1547 浏览次数: 16452
评审: Arsalan DaudiVinay PanwarAnonymous reviewer(s)
参见作者原研究论文
The authors used this protocol in:

Oct 2014
Advertisement










Abstract
The construction of a physical collection of open reading frames (ORFeomes) for genes of any model organism is a useful tool for the exploration of gene function, gene regulation, and protein-protein interaction. Here we describe in detail a protocol that has been used to develop the first collection of transcription factor (TF) and co-regulator (CR) open reading frames (TFome) in maize (Burdo et al., 2014). This TFome is being used to establish the architecture of gene regulatory networks (GRNs) responsible for the control of transcription of all genes in an organism. The protocol outlined here describes how to proceed when only an incomplete genome with partial annotation is available. TFome clones are made in a recombination-ready vector of the Gateway? system, allowing for the facile transfer of the ORFs to other Gateway?-compatible vectors, such as those suitable for expression in other host species. Although this protocol was developed for the maize TFome it can readily be applied to the generation of complete ORFeome collections in other eukaryotic species.
[Protocol overview] An important aspect of successful TFome generation is the initial effort spent to establish a reliable set of gene models so that they can be subsequently amplified or synthesized. An actual TFome construction protocol for a particular species will depend on available resources such as a full-length cDNA (flcDNA) collection and a reliable reference genome (Figure 1).
In the case of maize, a flcDNA collection and a draft genome was available, but the former provided only 30% of the needed clones, and the latter contained gaps and some erroneous gene models. In order to develop a near-complete set of target gene models for maize TFs, a bioinformatics pipeline was developed as described by Yilmaz et al. (2009). In brief, a two-pronged search process was developed. The first involved making a collection of protein sequences of TFs in other species and available from databases such as PlantTFDB, PlnTFDB and DBDTF. These sequences were then used to search gene models from the draft maize genome using BLASTP. The second process involved developing a collection of domains that define TF families and that are mostly annotated in the PFAM database (Finn et al., 2014). These domains were then used to search the draft maize genome using BLASTX. The number of TF families that exist and their naming is subject to change as new members are discovered and studied. Table 1 provides a list of known TF families with alternative names along with the respective PFAM domains whose presence or absence defines each TF family. HMM models for each domain can be obtained from the PFAM database (pfam.xfam.org). Following the BLAST search, redundant models are eliminated and then based on the TF motifs present in each gene model, gene models are assigned to a TF or Co-Regulator (CR) family according to the criteria specified in Table 1. Lastly, it is recommended to set up a database to store information on each TF family. The GRASSIUS (www.grassius.org) website was established to access the stored information on TF gene models for maize, sorghum, rice, Brachypodium, sugarcane and other grasses (Burdo et al., 2014). In the following section, an assumption is made that at least a draft genome or draft transcriptome is available and that a set of gene models is available that have been determined ab initio or with additional manual annotation. Familiarity with the use of PERL scripts is advantageous for the gene model assembly phase.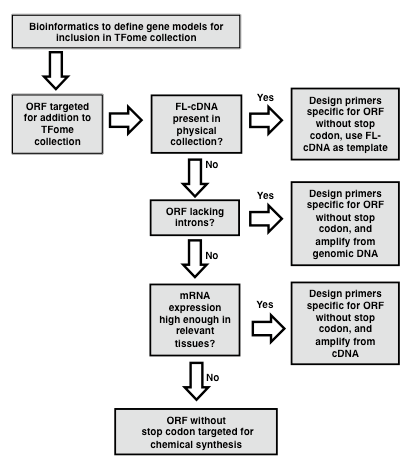
Figure 1. Flowchart for the generation of a TFome project. Flowchart outlining the general strategy for template identification, PCR amplification and cloning of transcription factor (TF) full length (FL) open reading frames (ORFs). (modified from Burdo et al., 2014)
Materials and Reagents
The main starting materials for embarking upon a large TFome project are the assembly of gene models and a collection of plasmid templates from existing cDNA collections. In this section, processes to develop these are outlined.
- Assembly of gene models and TF domain databases
- Assemble a collection of gene models from the available target genome. For plant genomes, the Phytozome database (phytozome.jgi.doe.gov) and EnsemblPlants (http://plants.ensembl.org/index.html) permit the downloading of all predicted protein models for a species as a single multi-sequence FASTA formatted file. For example, at the Phytozome website the BioMart tool permits one to select the genome dataset for a particular plant species. Once the genome is selected then attributes of the sequences to be downloaded can be specified such as peptide sequences or coding sequences only. By default all gene models are selected and then these can be downloaded as a single FASTA file that is the input file for subsequent steps below.
- Assuming the draft quality of the transcript annotation it would be desirable to eliminate redundant gene models in a multiseq FASTA file. The GRASSIUS website provides the custom perl script “IdentifySeqRedundancy.pl” (http://grassius.org/tools.html) for this purpose. This script also requires the perl module “Digest::MD5” which is available from the Comprehensive Perl Archive Network (CPAN) website (http://search.cpan.org/dist/Digest-MD5/MD5.pm). One can also eliminate redundant models within the species using BLAST searches. Proteins were arbitrarily considered duplicated if they are found in the same species, with a query coverage ≥ 90%, or have a query identity ≥ 90% and the query alignment starts less than 9 residues from the start codon. Alternatively, more complex criteria such as those of Gu et al., 2002, may be employed to identify duplicate proteins in a genome. If these conditions are satisfied, the longest protein is kept and the eliminated proteins were classified as identical or splicing variants. If there is access to RNA-Seq datasets they may be used to corroborate target TF gene models, but such an approach is not outlined here. Targeting the longest splice variant which is supported by EST or RNA-Seq data provides the maximum protein interaction space for identifying the protein-DNA and protein-protein interactions that gene regulatory networks are comprised of.
- Scanning the non-redundant multifasta file against a collection of protein domains as hidden Markov models (HMMs) such as provided by PFAM or Interpro provides a protein domain annotation of the putative proteome. For this particular step the software HMMER is required. In brief HMMER is a set of tools implementing the profile hidden Markov models to find similarity across protein sequences and is necessary to search the PFAM HMM models in a group of protein sequences. It is possible to call HMMER from a variety of scripting languages such as perl or python, using pre-build HMMER wrappers. PFAM provides one of those scripts written in perl (pfamscan.pl) with a set of PFAM pre-established parameters. Source code may be downloaded from the following website ftp://ftp.sanger.ac.uk/pub/databases/Pfam/Tools/PfamScan.tar.gz. Table 1 is a compilation of protein domains that have been used to define TF and CR families in plants (Buitrago-Florez et al., 2014; Burdo et al., 2014; Perez-Rodriguez et al., 2010; Yilmaz et al., 2009). This table describes 62 TF and 26 CR families that were used in defining gene models for inclusion in the maize TFome. Twelve of these families do not have ascribed PFAM domains but can be defined using “in house” HMMs as previously described (Buitrago-Florez et al., 2014; Perez-Rodriguez et al., 2010). The HMMs for the CCAAT-Hap2, 3, and 5 TF families can be obtained from the AGRIS database (http://arabidopsis.med.ohio-state.edu) (Yilmaz et al., 2011).
- Once the primary list of gene models are annotated with protein domains, they are assigned to TF or CR families using the criteria outlined in Table 1. The criteria include identifying the presence of one or more motifs and the absence of other (forbidden) motifs (Buitrago-Florez et al., 2014; Perez-Rodriguez et al., 2010; Yilmaz et al., 2009). The annotation involves a custom perl script “get_InterProScanDomains.pl” to sort proteins into TF families based on the interproscan output and is available at the GRASSIUS website (http://grassius.org/tools.html). The script keeps only significant hits with e-value ≤ 0.001 and verifies that the rules as defined in Table 1 are fulfilled. When the rules are only partially fulfilled then the protein is assigned into “Orphan” TFs. This can be the largest class of TFs for a species (~11.7% of the maize TFome), until Orphan members are assigned to families.
- Searches can be conducted with local computation resources or when not available using the iPlant Collaborative Discovery Environment public resource (http://www.iplantcollaborative.org).
- Assemble a collection of gene models from the available target genome. For plant genomes, the Phytozome database (phytozome.jgi.doe.gov) and EnsemblPlants (http://plants.ensembl.org/index.html) permit the downloading of all predicted protein models for a species as a single multi-sequence FASTA formatted file. For example, at the Phytozome website the BioMart tool permits one to select the genome dataset for a particular plant species. Once the genome is selected then attributes of the sequences to be downloaded can be specified such as peptide sequences or coding sequences only. By default all gene models are selected and then these can be downloaded as a single FASTA file that is the input file for subsequent steps below.
- Screening of EST or flcDNA collections for plasmid templates
- Identify which cDNA resources are available for the target genome (see Note 1). Most genome projects for model species include generating an EST library, although many libraries are not publically available. For the maize TFome, extensive use of the maize flcDNA collection (http://www.maizecdna.org) was made (Soderlund et al., 2009). Individual cDNA clones for this library and many other plant species are available through the Arizona Genomics Institute (http://www.genome.arizona.edu).
- Using the coding sequence of a gene model as a query sequence, ESTs or flcDNAs were then identified using BLASTP or BLASTX, for which the amino terminus, including the start codon, was present and the sequence alignment was >99%. Alignments that are not 100% identical may occur because EST sequences are not high fidelity due to sequencing errors particularly at the 3’ end of sequences (Soderlund et al., 2009). Alternatively spliced isoforms not represented by a transcript model may also be targeted, as long as they maintain the reading frame of the original transcript.
- Once a likely flcDNA template is located, then the plasmid is acquired, isolated and sequenced from each end to confirm that: a) it is the correct template, and b) it is full length. Some cDNA libraries utilize enzymes during their construction that cut within the coding sequence leading to partial clones, which would be unsuitable for amplification of the entire coding sequence.
- Once a suitable target plasmid template is identified for a target gene, then a sample is diluted to 1 ng/µl and 1 ng is sufficient as template in a PCR reaction.
- Identify which cDNA resources are available for the target genome (see Note 1). Most genome projects for model species include generating an EST library, although many libraries are not publically available. For the maize TFome, extensive use of the maize flcDNA collection (http://www.maizecdna.org) was made (Soderlund et al., 2009). Individual cDNA clones for this library and many other plant species are available through the Arizona Genomics Institute (http://www.genome.arizona.edu).
- Other reagents
- One Shot® TOP10 chemically competent cells (Life Technologies, catalog number: C404003 )
- PureLink® Plant RNA Reagent (Life Technologies, catalog number: 2322-012 )
- Turbo DNA-free™ kit (Life Technologies, Ambion®, catalog number: AM1907 )
- Thermo Scientific Maxima H minus 1st strand synthesis kit (Thermo Fisher Scientific, catalog number: K1652 )
- Ribolock® RNase inhibitor (Thermo Fisher Scientific, catalog number: EO0382 )
- EmeraldAmp® MAX PCR Master Mix (Takara Bio Company, catalog number: RR320A )
- Phusion® high fidelity polymerase (New England Biolabs, catalog number: M0530S )
- Gateway® pENTR™/D-TOPO® or pENTR™/SD/D-TOPO® vectors (Life Technologies, catalog numbers: K243520 and K242020 respectively)
- Genscript® Taq Polymerase (GenScript USA Inc., catalog number: E000071000 )
- EmeraldAmp® MAX PCR Master Mix (Takara Bio Company, catalog number: RR320A)
- 1 kb ladder molecular weight size standards (Thermo Fisher Scientific, catalog number: SM0311 )
- RNA extraction buffer I (see Recipes)
- RNA extraction buffer II stock solutions (see Recipes)
- RNA extraction buffer II (working solution) (see Recipes)
- Carlson lysis buffer (see Recipes)
- Freezing medium (see Recipes)
- One Shot® TOP10 chemically competent cells (Life Technologies, catalog number: C404003 )
Equipment
Note: Most equipment listed here is standard molecular biology instrumentation present in most laboratories. A large TFome project would also benefit from the use of multichannel pippetters and 96 well plate formatted experimentation.
- Microcentrifuge
- High speed centrifuge
- Gradient thermocycler
- Gel electrophoresis equipment
- Water baths
- -80 °C freezer for the storage of stocks
- Aerosol pipette tips recommended for all DNA manipulation and cloning experiments
- Wizard® SV 96 Plasmid DNA Purification System (Promega Corporation, catalog number: A2255 )
- Wizard® Plus SV Minipreps DNA Purification System (Promega Corporation, catalog number: A1330 )
- Wizard® SV Gel and PCR Clean-Up System (Promega Corporation, catalog number: A9281 )
- Gene synthesis (Life Technologies)
- 2 ml 96 well culture dish (Thermo Fisher Scientific, catalog number: 12566121 )
- Breathable plate seal (Thermo Fisher Scientific, catalog number: AB0718 )
- 0.5 ml plates (USA Scientific, catalog number: 18965000 )
- 7 mm sized silicone seal that can be re-autoclaved (Thermo Fisher Scientific, catalog number: 0339649 )
- Matrix sample storage system (matrixtechcorp.com, Thermo Fisher Scientific, catalog numbers: 4111MAT ) (Capit-All® Capper/Decapper), 3740 (Barcoded screw cap tubes), and 4477 (Screw cap tray)
- (Optional) Vac-Man® 96 Vacuum Manifold (Promega Corporation, catalog number: A2291 ) for 96 well plasmid preparation
- (Optional) Vacuum pump capable of generating 38-51 cm of Hg or equivalent
Software
- OligoAnalyzer 3.1 software (www.idtdna.com)
Procedure
文章信息
版权信息
© 2015 The Authors; exclusive licensee Bio-protocol LLC.
如何引用
Gray, J., Burdo, B., Goetting-Minesky, M. P., Wittler, B., Hunt, M., Li, T., Velliquette, D., Thomas, J., Agarwal, T., Key, K., Gentzel, I., Brito, M. D. S., Mejía-Guerra, M. K., Connolly, L. N., Qaisi, D., Li, W., Casas, M. I., Doseff, A. I. and Grotewold, E. (2015). Protocol for the Generation of a Transcription Factor Open Reading Frame Collection (TFome). Bio-protocol 5(15): e1547. DOI: 10.21769/BioProtoc.1547.
分类
系统生物学 > 基因组学 > 外显子组捕获
系统生物学 > 基因组学 > 测序
植物科学 > 植物分子生物学 > DNA > DNA 测序
您对这篇实验方法有问题吗?
在此处发布您的问题,我们将邀请本文作者来回答。同时,我们会将您的问题发布到Bio-protocol Exchange,以便寻求社区成员的帮助。